Hands-On Projects
AI Model CI/CD Pipeline (MLOps)
GitHub ActionsTerraformEKSECRDockerKustomizeCanary DeployPrometheusPythonvLLMS3IAM OIDC
Built a complete MLOps CI/CD pipeline for deploying LLM models on AWS EKS with canary deployments and automated rollback. The pipeline features a three-stage workflow: CI (linting, unit tests, model evaluation against quality thresholds for latency, throughput, and accuracy), staging deployment with smoke tests, and production canary rollout (10% → monitor → promote or rollback). Infrastructure is managed via Terraform (ECR, S3 with lifecycle policies, IAM with GitHub OIDC for keyless auth). Kubernetes manifests use Kustomize overlays for environment-specific configs. An automated model evaluation framework compares each deployment against baseline quality scores, gating production releases on p95 latency < 5s, throughput > 50 tokens/sec, and error rate < 1%. Includes a version tracker storing deployment history in S3 for audit and rollback.
📖 Read blog post →
Mistral RAG Assistant
FastAPIReactQdrantMistral AIDockerTypeScriptRAGVector DBLLMGitHub Actions
Built a production-ready Retrieval-Augmented Generation application that lets users upload documents (PDF, DOCX, TXT, Markdown) and ask questions with source-cited answers. The system features recursive document chunking with overlap, batch embedding via Mistral's mistral-embed model (1024 dimensions), cosine similarity search over Qdrant, and RAG-augmented generation with streaming responses. Includes a built-in evaluation framework measuring retrieval precision, answer relevance, faithfulness, and correctness. The React frontend provides a chat interface with collapsible source panel, drag-and-drop document upload, and an evaluation dashboard. Fully containerized with Docker Compose and CI/CD via GitHub Actions to AWS ECS.
📖 Read blog post →
Mistral LLM Inference Platform on AWS EKS
EKSTerraformHelmvLLMGPU (A10G)FastAPIPrometheusDockerGitHub ActionsSpot InstancesHPA
Designed and deployed a production-grade LLM inference platform serving Mistral 7B Instruct on AWS EKS with GPU-accelerated inference via vLLM. The architecture features a FastAPI gateway with bearer token authentication and per-IP rate limiting, proxying OpenAI-compatible requests to a vLLM backend running on NVIDIA A10G GPUs (Spot instances for 60-70% cost savings). Infrastructure is provisioned via Terraform (VPC, EKS, ECR, managed node groups with AL2023 NVIDIA AMI), deployed with Helm charts, and monitored with Prometheus metrics and Grafana dashboards. Autoscaling is driven by a custom HPA metric (pending inference request queue depth). CI/CD pipelines implement canary deployments with automated smoke tests and rollback. Load testing with Locust validated 0% failure rate at ~3.4s p50 latency for 100-token completions.
📖 Read blog post →
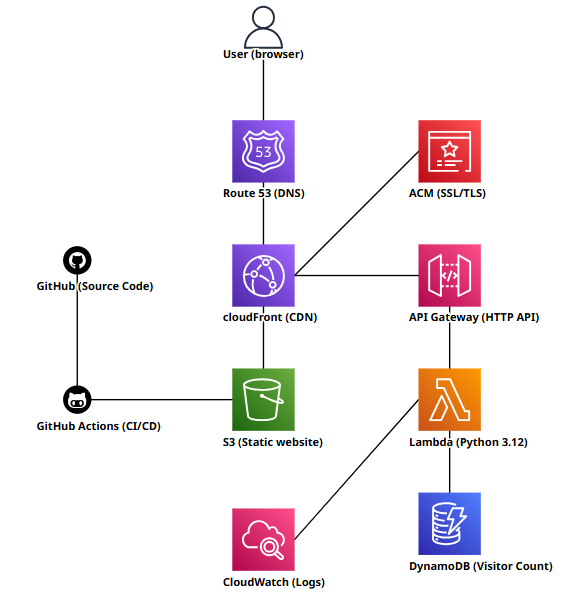
AWS Cloud Resume Challenge
S3CloudFrontRoute 53DynamoDBLambdaAPI GatewayCloudFormationGitHub Actions
Built and deployed a full-stack serverless personal website on AWS. Static files are hosted in S3 and served globally through CloudFront with a custom domain and HTTPS via ACM. A visitor counter is powered by a Lambda function (Python) backed by DynamoDB, exposed through API Gateway and routed via CloudFront. The entire infrastructure is defined as code using CloudFormation and deployed with a single script. A GitHub Actions CI/CD pipeline automatically syncs website updates to S3 and invalidates the CloudFront cache on every push to main.
📖 Read blog post →
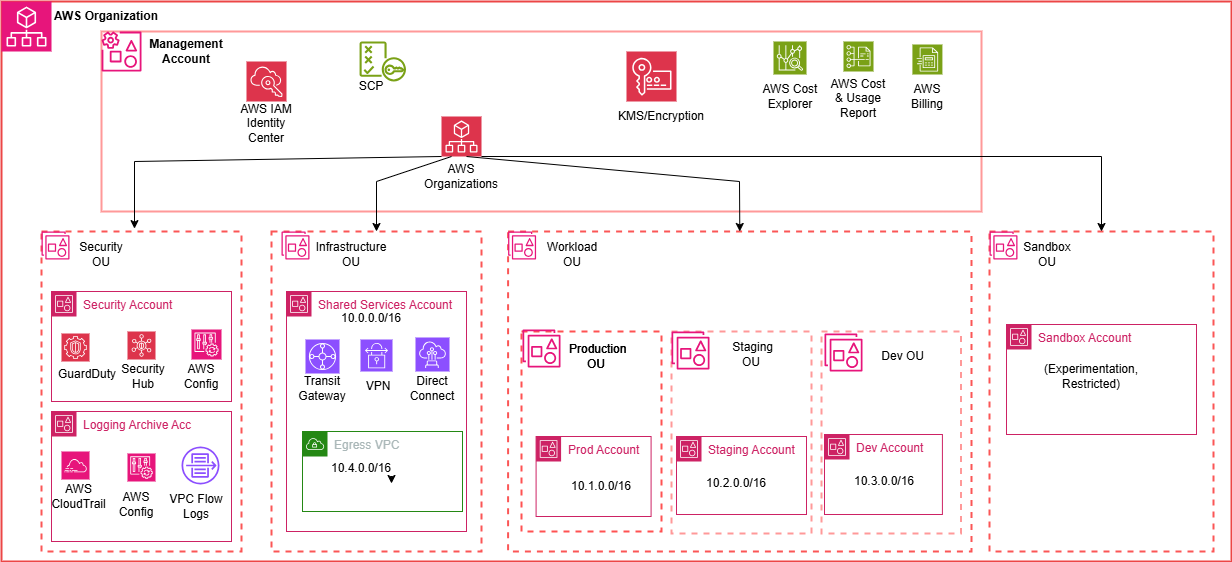
Secure Multi-Account AWS Landing Zone for Banking
TerraformAWS OrganizationsTransit GatewayKMSSecurity HubGuardDutyCloudTrailDirect ConnectS3 Object LockIAM Identity Center
Designed and implemented a production-grade AWS Landing Zone for French banking institutions subject to DORA and RGPD regulations. The architecture provisions seven dedicated accounts across four OUs, with centralized security monitoring, immutable audit logging (365-day S3 Object Lock), hub-and-spoke networking via Transit Gateway with route table segmentation, dual-path hybrid connectivity (Direct Connect + VPN), and cross-region disaster recovery (RTO 4h, RPO 1h). Six Service Control Policies enforce compliance guardrails including region restriction, encryption enforcement, and service allowlisting. The entire infrastructure is codified in 10 reusable Terraform modules with a simulation mode for single-account testing.
📖 Read blog post →
WordPress Application Deployment
VPCEC2RDSEFSALBAuto ScalingRoute 53ACMNAT Gateway
Designed and deployed a highly available WordPress application for a medium-sized business on AWS. The architecture spans two Availability Zones with a VPC containing public and private subnets. An Application Load Balancer distributes traffic to EC2 instances running in an Auto Scaling group across private subnets. Amazon RDS (Multi-AZ) provides a managed, fault-tolerant MySQL database, while Amazon EFS provides shared storage for WordPress media files across all instances. NAT Gateways in the public subnets enable outbound internet access for the private instances. Route 53 handles DNS routing and ACM provides HTTPS encryption.
Gen AI Spending Analyst Agent
Amazon BedrockConverse APIClaude 3Tool UsePythonMatplotlib
An AI-powered spending analysis agent built with Amazon Bedrock's Converse API and the tool use pattern. The agent reads transaction data from CSV files, categorizes expenses using keyword matching, calculates budgets with date-range filtering, and generates visual charts (pie and bar) — all through natural language conversation. The CLI-based agent uses a multi-turn conversation loop where Claude decides which local Python tools to call based on the user's question, executes them locally, and interprets the results in plain English. Built as a learning project to explore the fundamentals of building AI agents with function calling.